Dimension Design
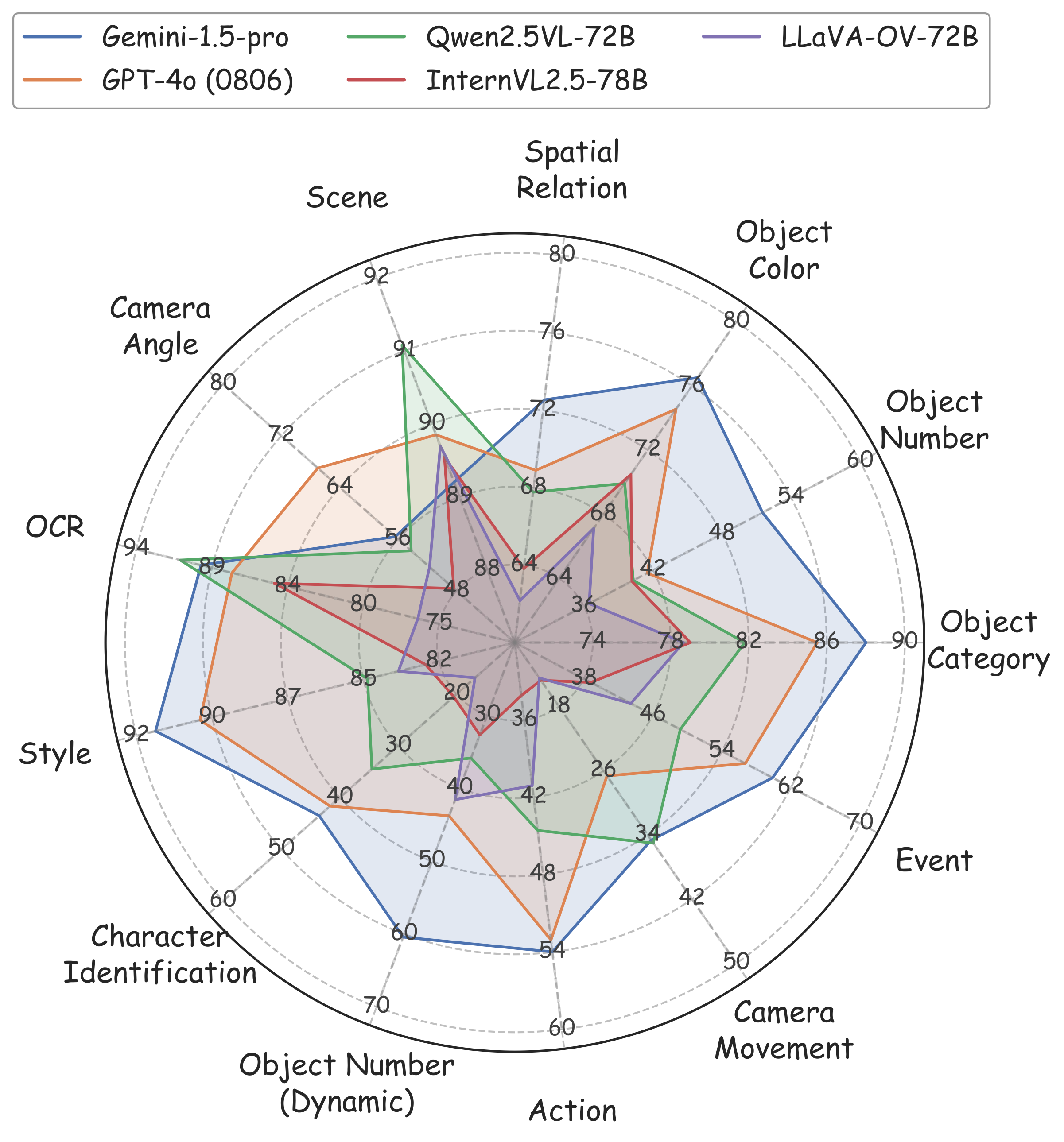
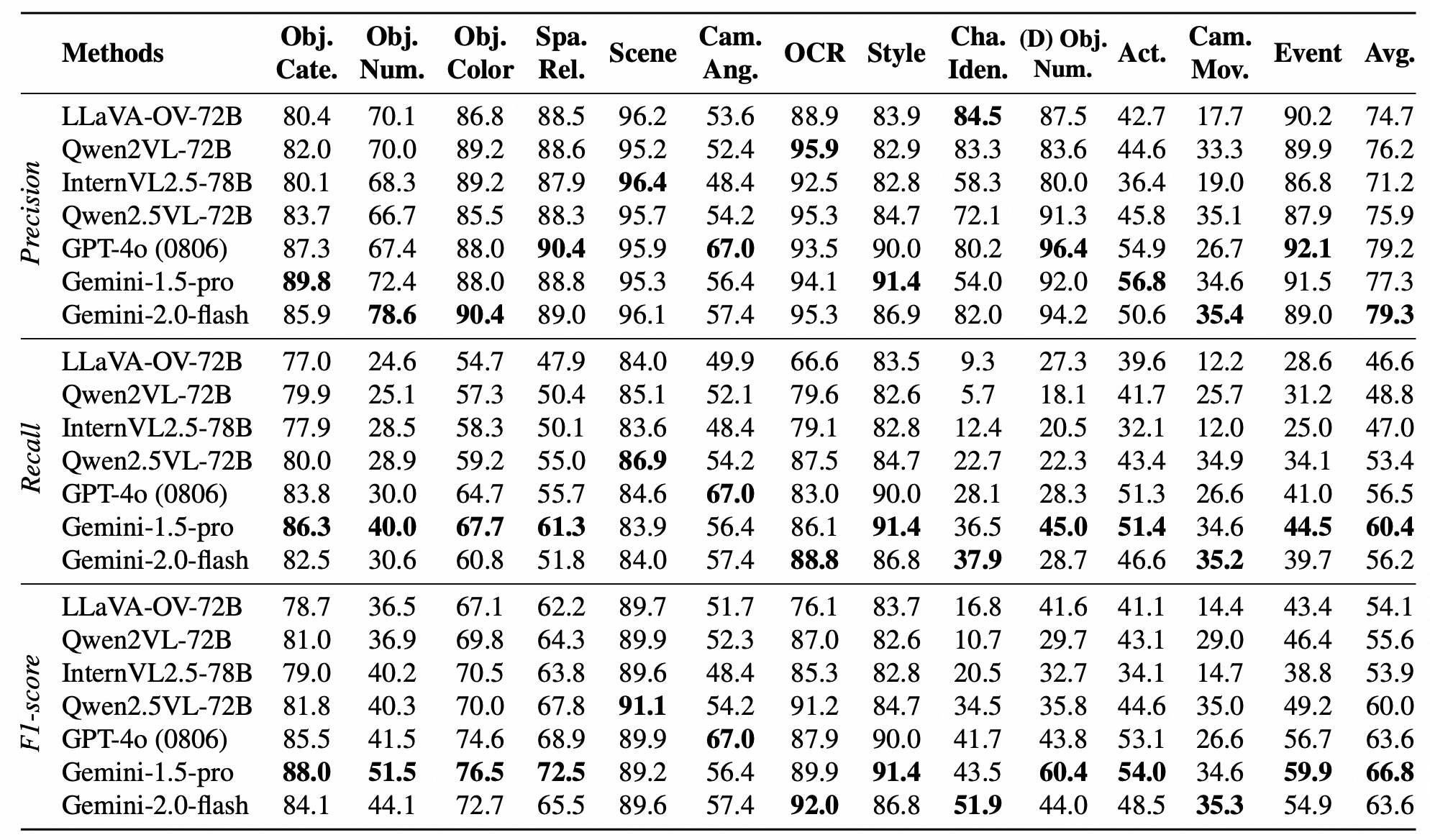
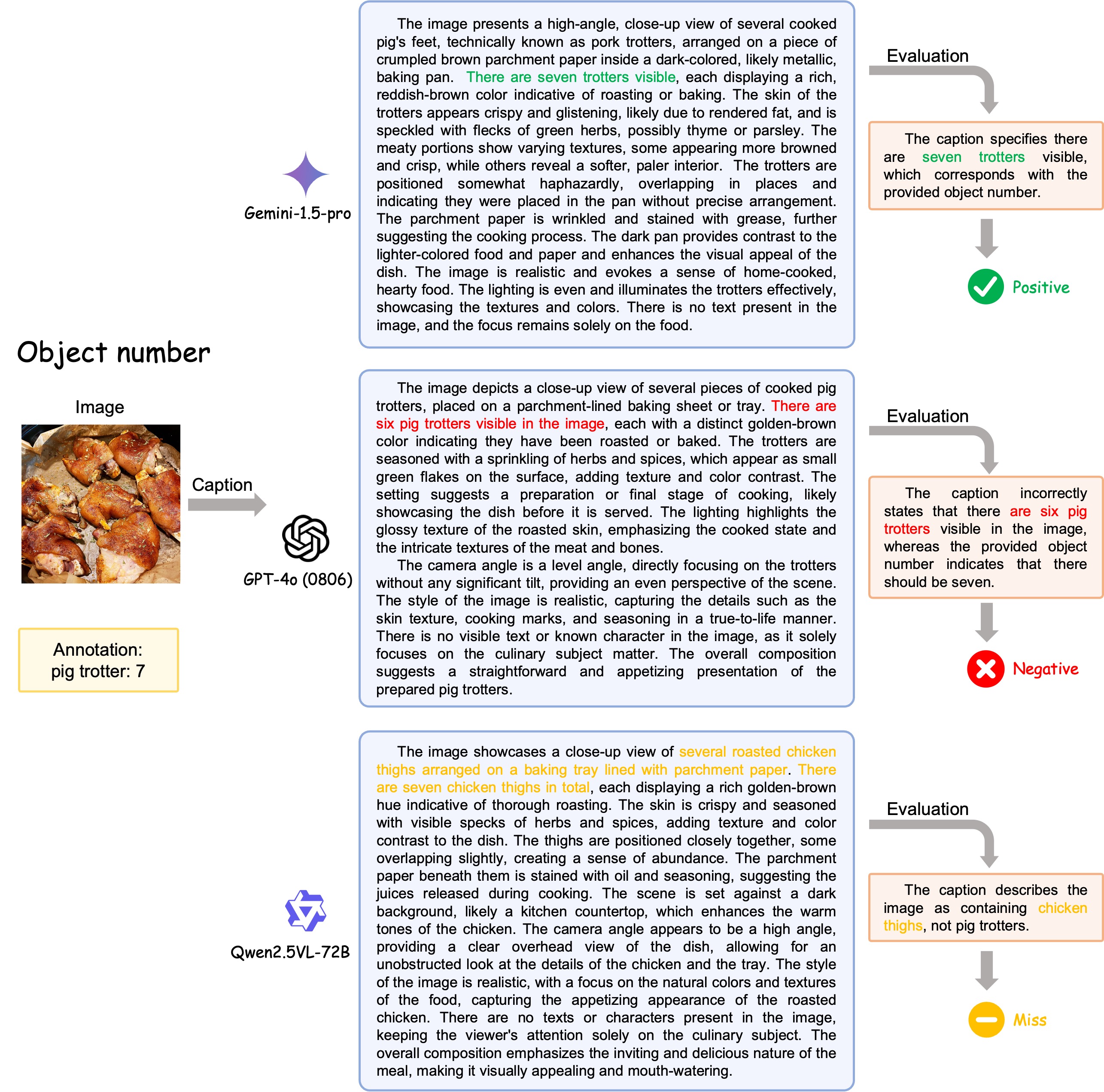
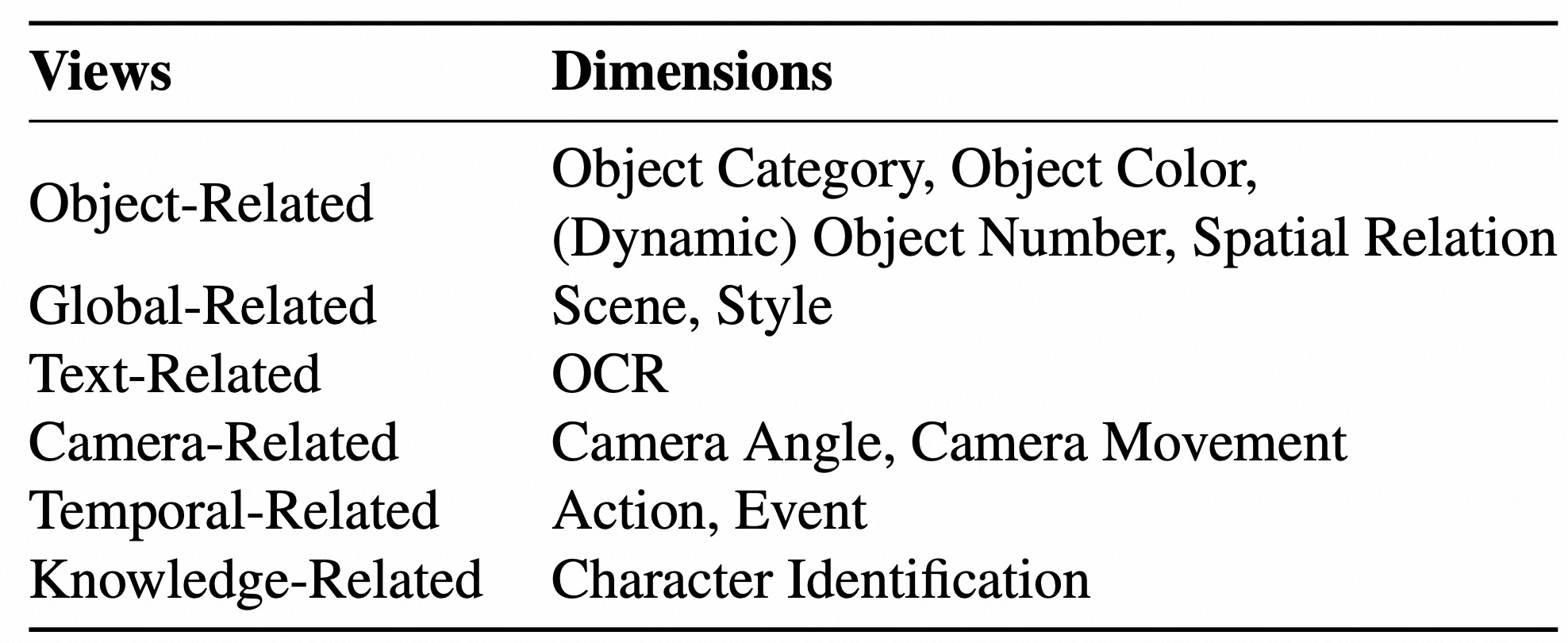
An example of image caption (left) and video caption (right). By analyzing the components of captions, we conclude 12 dimensions (9 static dimensions and 4 dynamic dimensions with object number shares on both static and dynamic), which all contribute to a detailed and comprehensive caption. The static dimensions are shared in both images and videos. For video data, there are additional dynamic dimensions as they need to be judged with temporal relations.

Benchmark Statistics
The data source count and distribution of each dimension. We collect nearly 1,000 images/videos for each dimension, crawl parts of data by ourselves, and sample some data from existing datasets to ensure diversity.
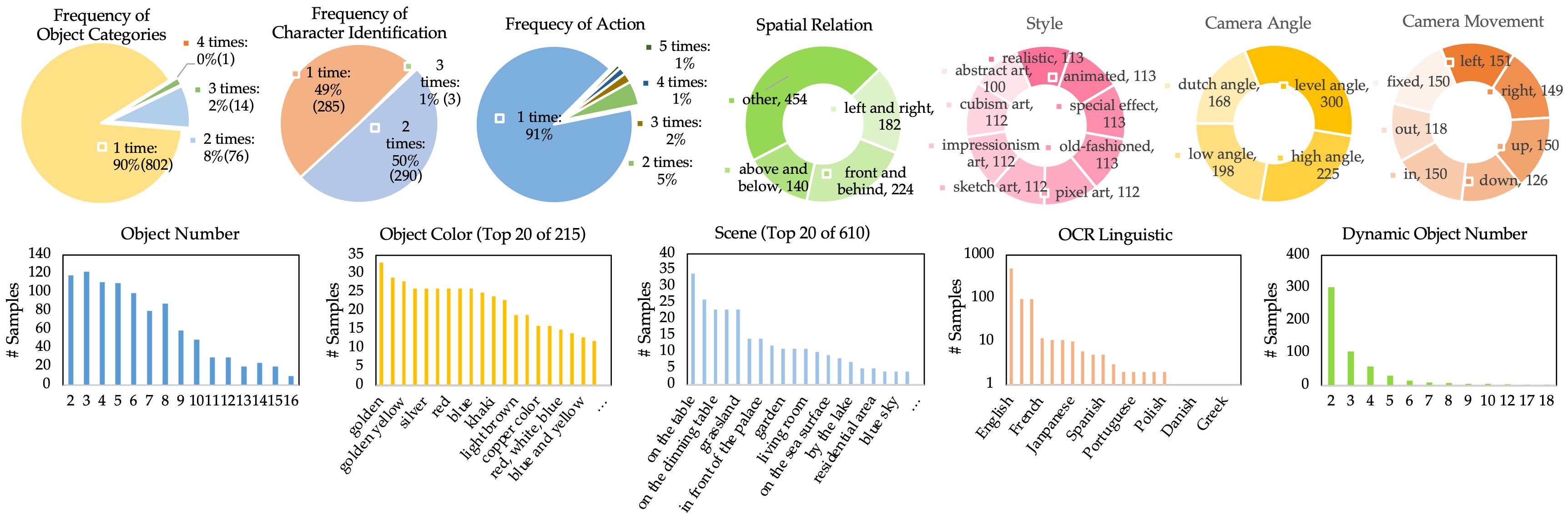
The annotation distribution of each dimension. We statistic different dimensions with different types. We count the frequency in object categories, character identification, and action as most of the descriptions only appear one time. For spatial relation, we summarize 4 categories and count their numbers. For style, camera angle, and camera movement, we count the samples of each category. For others, we plot bar charts to count and show the most frequent samples.